
回顾过去,「比大更大」(Bigger than bigger)这句广告词曾鲜明地描绘了苹果公司的创新精神。然而,现在这句话同样贴切地形容着AI领域最热门的大语言模型。这些庞大的AI模型的参数规模逐渐攀升,从十亿、百亿到千亿,让人瞠目结舌。OpenAI的GPT系列便是典型代表,从GPT-1到GPT-3,模型训练所需的数据集也从4.5GB迅猛扩张至570GB。然而,如今,专家们却在预测高质量的文本数据可能在2023-2027年之间将面临枯竭,这将对AI训练带来严峻挑战。
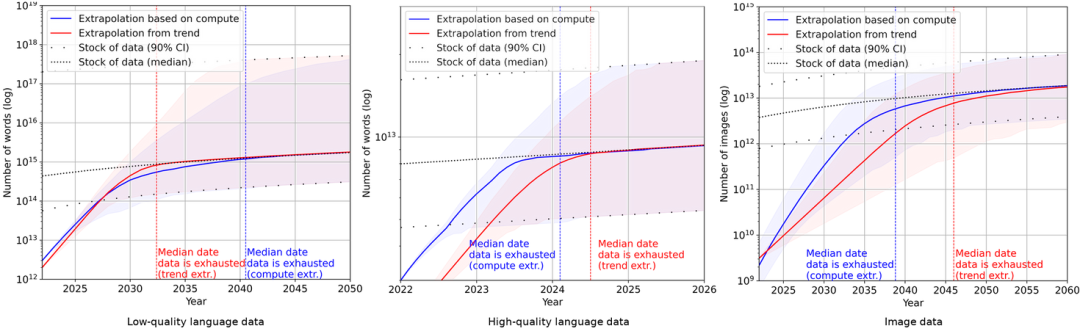
低质量文本、高质量文本和图像的机器学习数据消耗和数据生产趋势
不久前的 Databricks 举办的 Data+AI 大会上,a16z 创始人 Marc Andreessen 认为, 随着互联网的发展,海量的数据积累为AI的崛起奠定了基础。然而,这样的兴旺势头也带来了新的问题。在数据不断扩充的同时,人们也开始反思这种数据扩张趋势对未来的影响。随着时间的推移,高质量的人工生成数据将变得越来越难以找到。一些研究人员担忧,在AI领域,「干净的人类数据集」可能会愈发稀缺,不可避免地将逼迫AI转向其他数据来源。
一、AI「近亲繁殖」将导致「模型崩溃」
在《递归的诅咒:用生成数据训练会使模型遗忘》这篇论文中,研究人员对「模型崩溃」进行了深入探讨。他们发现「模型崩溃」是模型几代退化的过程。在早期阶段,模型开始逐渐丧失对原始数据分布的了解,也就是所谓的「干净的人类数据」。然而,更加令人担忧的是,晚期阶段模型会将前几代模型对原始数据分布的「错误认知」纠缠在一起,导致模型对现实产生曲解。
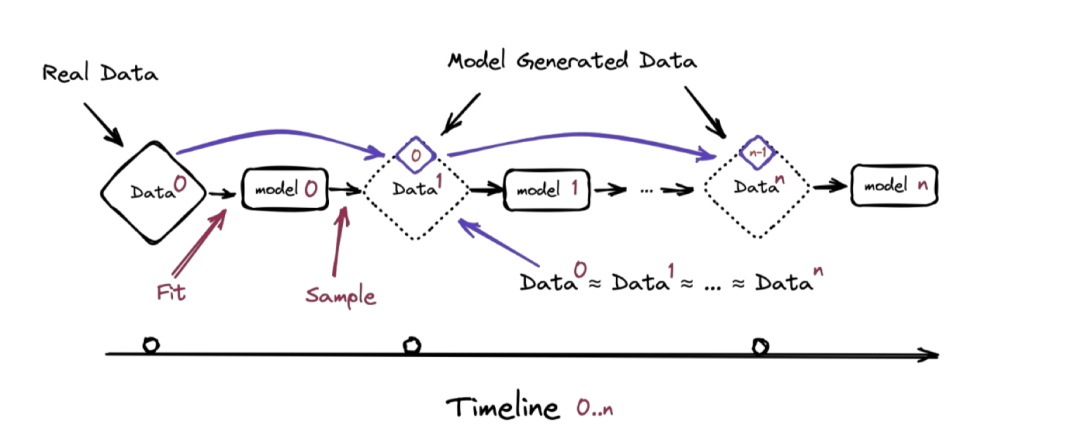
模型迭代示意图
从理论上来说,这样的「近亲繁殖」将导致人工智能生成的数据中的错误不断累积,使得主要模型在接受这些数据训练后,对现实的认知逐渐失真。虽然研究团队也承认分析方法有一定局限性,模型的准确性也会受到影响,但不可否认的是,AI对数据集的消耗速度确实让人感到担忧。
二、为什么会模型崩溃?
「模型崩溃」产生的原因主要在于AI并非真正的智能,其展现出的近似「智能」实际上是基于大量数据的统计学方法。在AI的训练过程中,模型更倾向于重视出现概率较大的数据,而较小概率的数据则容易被忽略。举个例子来说,如果我们需要记录100次骰子的投掷结果来计算每个面出现的概率,理论上每个面出现的概率是相同的。然而,由于样本量较小,可能3和4的情况出现较多。但对于模型来说,它学习到的数据将导致3和4的概率被高估,从而产生更多3和4的结果,这是「模型崩溃」的一种表现。
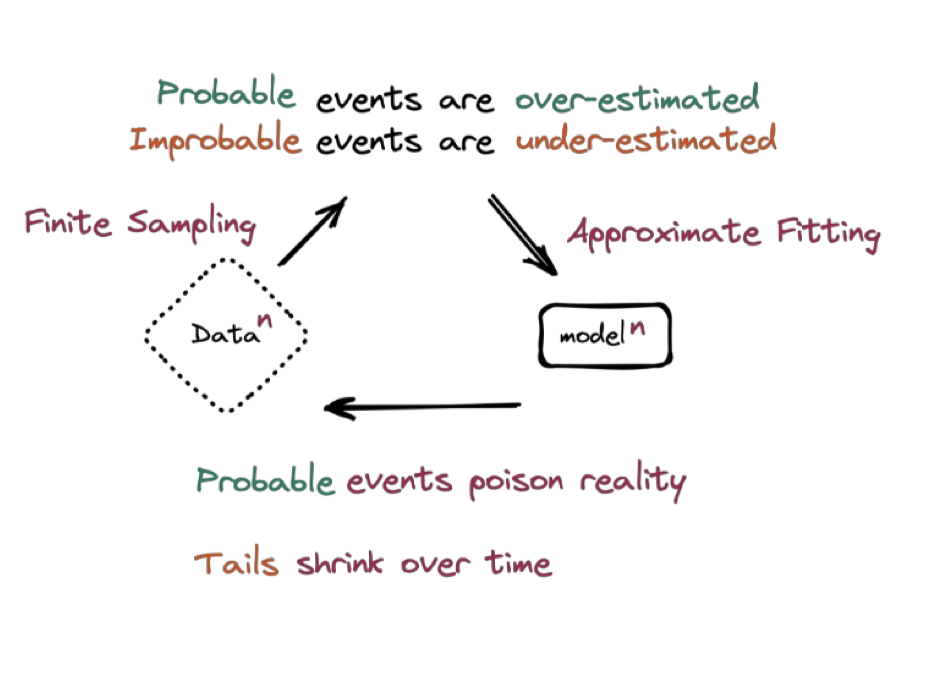
模型崩溃示意图
另一个次要原因是函数近似误差。真实函数通常十分复杂,但在实际运用中,为了简化计算,往往会使用近似函数来代替真实函数。这就导致了近似误差的产生,使得模型的准确性受到影响。
三、面对模型崩溃,AI训练怎么办?
尽管面临着人类数据枯竭和「模型崩溃」的挑战,AI训练并非没有解决之道。
1、合成数据
一种方式是使用合成数据,专业基于AI生成的数据早已被成功应用于AI的训练。事实上,现实中很难找到完全干净且高质量的数据,而利用合成数据则能弥补数据的不足。然而,这其中需要一整套体系来区分AI生成的数据中哪些是可用的、哪些是不可用的,并根据训练后模型的效果进行反馈和调整。OpenAI便在GPT-4的训练中采用了大量由GPT-3.5生成的数据来进行训练,而在未来,合成数据将成为源源不断的有效数据来源。
2、数据「隔离」
另一种方法一种方法是数据「隔离」,即保留对干净的人工生成数据源的访问,将AI与之分隔开。这需要社区和公司的共同合作,共同维护人类数据的纯净性,以防止被AI污染。

对于AI行业而言,合成数据已经成为一个共识,其广泛应用不仅局限于文字和图片,例如自动驾驶、机器人等行业对于合成数据的需求量将远远大于文本数据。同时,AI的三大要素,即数据、算力、算法,如今数据来源已经得到解决,算法和算力的进一步发展相信也能顺利跟进。
总体而言,AI领域的发展离不开对数据的依赖,而解决数据枯竭和「模型崩溃」的问题将成为AI发展的重要里程碑。「隔离」数据和合成数据的应用将为未来AI训练提供有力支持,随着技术的不断进步和创新,相信AI行业将能够克服挑战,开拓出更加辉煌的未来。